Anthropic’s AI Claude hacked into three organizations during cybersecurity test
Recently I read:
Drifting SpaceX rocket heading for accidental collision with moon
The tangled financial web at the heart of Reform UK: ‘Sources have described how staff at several different banks were so concerned about a range of transactions…that they reported them to the National Crime Agency’.
Latest posts:
Temporarily housed Britons refused usage of air conditioning by landlords; children suffer
Sometimes news comes that really confirms my worst prejudices against certain communities. In this case I’m talking about the moral vacuums that are companies that profiteer via offering accommodation to those who most desperately need it, aka a certain category of landlord.
The first paragraph says it all:
Homeless families placed in temporary accommodation in London were told they could not use the in-built air conditioning as it had “not been offered as an amenity” for them, leading to two children being hospitalised during recent heatwaves.
This despite the fact that it seems like the building design itself exacerbates the very issues the residents are trying to mitigate.
Residents say the all-glass construction of the block and the fact that windows open only slightly mean that, without air conditioning, their flats have become unbearably hot.
“It is very difficult to cool the flats down,” one person said. “I find that as soon as I enter the building, I become much hotter, start feeling sick and sweat profusely.”
Remembering that the vulnerable homeless families that are forced into temporary accommodation due to a lack of state willingness or ability to actually solve the scourge of homelessness once and for all do, of course, not get to choose where to live .
After the scandal broke it seems like the restrictions have been lifted. Well, in a theoretical “the on button now works” sense anyway.
However, some residents said they were informed that if they used the system they would be billed via a standing charge rather than for how long the air conditioning ran, which could result in bills of up to £500 for the summer.
I have to imagine that a homeless family in temporary accommodation is unlikely to have a spare £500 - so now they are forced to make the cooling counterpart to the standard “heating or eating” choice an unacceptable high number of Britons have to regularly make. This is not a triviality. Heat kills. Nearly 3000 people in the May and June heatwaves we’ve just suffered.
The building in question has form in extremely dubious ethical practices:
The 19-storey glass-fronted block is owned by Criterion Capital, set up by the billionaire property magnate Asif Aziz. The company was accused this year of trying to mass-evict tenants shortly before no-fault evictions were banned, something it has denied.

The greatest mystery of all.
(Original source unknown to me)
Uh oh, it’s back :(
Britain braces for fourth heatwave of year as fire chiefs issue public appeal
Temperatures are forecast to reach as high as 35C…
July has been 3C above average across the UK, according to provisional Met Office data, and with more than a month of summer left, the UK has already faced more days above 30Cthan ever before.
Hot and dry of course:
Southern England has had just 1% of its average July rainfall, while England as a whole has had 5% and the UK 20%, according to the Met Office.
You cannot possibly worship Thatcher and MAGA at the same time
It’s not the main focus of the article, but Rafael Behr raises a good point in that it’s very inconsistent for someone to venerate both Thatcher and Trump at the same time - which is exactly what the more radical (increasingly mainstream) UK Conservative MPs and their dwindling supporters claim to do to various extents:
What British conservatives either fail to observe or refuse to acknowledge in their mindless orbit around Planet Trump is that Maga politics contains more heresies against the sacred Thatcherite creed than anything Burnham proposes. The US president hates free trade. He admires single-party regimes where a supreme ruler directs economic activity. He imposes arbitrary tariffs. He uses his office to extort money from private companies or coerce them into giving equity stakes to his government. And he acquired the power to do all of this by skilfully manipulating economic and social grievances caused by deindustrialisation - the alienation and dislocation felt by working-class communities that felt their security and dignity washed away by cold global market tides.
Worship Thatcher if you really must, despite the destruction her path ended up wreaking upon our nation. Kneel in anti-British, anti-patriotic sycophancy to Trump if you really must. You just can’t do both.
🎶 Listened to Blood on the Silver Screen by SASAMI.
This is the third album from SASAMI, an artist who appears to massively re-invent her genre of interest on every album. This one is more an indie-pop style entry, after she took the time to use her classical music training to study the art-form.
Out of interest, her key takeaway:
“For me, the unifying thing about pop — whether it’s Pulp or David Bowie or Beyoncé or Rihanna — the thing that makes it pop, I think, is that it makes the listener feel like a main character.”
🎶 Listened to All That Is Over by Sprints.
The second album from this Irish band, frequently featuring the punky frustration and anger of dealing with the inner and outer chaos and turmoil of modern-day life.
Let’s go with Rage, featuring the “guess who it’s referring to” lyric:
There’s a false prophet in the room Using fear as a weaponised tool
(Not that there’s a shortage of potential folk in that category.)
Albums worth listening to: 2026 releases (so far, non-exhaustive)
Here are some albums released this year that I’ve quite liked.
(as well as a test of whether my blog plugin to display albums in a grid works)

RADICALGavin Prophet · 2026

HELP(2)Fontaines D.C. & War Child Records · 2026
Be Someone BetterRed Arrow Highway · 2026

Romanticize The DiveMetric · 2026

Nine Inch NoizeNine Inch Nails & Boys Noize · 2026

Oversharing on the InternetEarth to Eve · 2026

LAURENLauren Sanderson · 2026

you seem pretty sad for a girl so in loveOlivia Rodrigo · 2026
![TRAUMACORE (RAW AND UNCUT) [DELUXE] by SkyDxddy](https://thebraindumpblog.com/uploads/2026/skydxddy-traumacore-raw-and-uncut-deluxe.jpg)
TRAUMACORE (RAW AND UNCUT) [DELUXE]SkyDxddy · 2026

The Wow! SignalMuse · 2026

Daughter from HellGracie Abrams · 2026

Cruel WorldHolly Humberstone · 2026

Music, Fashion, FilmCharli xcx · 2026
Yet another 'you can't trust cloud services with your data' example, Microsoft edition.
Here’s one more near-perfect example of the whole ‘if you don’t store no-DRM versions of all the digital artefacts that you care about on a disk that you 100% control then you’re at risk’ theme that I wish would be made more clear to more people. Digital sovereignty is not just for nation-states!
Anyway, a hacker got into Joshua Khane’s Microsoft account. Well, tried to. Luckily Microsoft flagged it as suspicious.
Unluckily that meant that they disabled Khane’s account entirely so even he couldn’t access it any more.
How much of a problem was this ? Well, he was a fairly engaged Xbox and OneDrive user so:
The automated suspension locked him out of everything - Xbox profile, a quarter-century of purchased games, and OneDrive files including baby photos of his son.
One can’t blame anyone who uses Windows for being a OneDrive user of course now that Microsoft virtually force you to be.
When he contacted them, Microsoft said sorry but that’s life, we can’t help:
Microsoft’s initial response: irreversible. No exceptions. Standard support offered no path back.
And that’s of course where the story ends for the vast majority of people who find themselves in situations like this.
Thankfully for Joshua it turns out that 1) Microsoft are liars, it wasn’t at all irreversible and 2) he knows how to craft a social media post that can go viral.
The official Xbox account responded, apologized, and eventually reinstated everything - purchases and data intact. The turnaround from “irreversible” to “restored” happened only after viral visibility forced Microsoft’s hand.
There are multiple lessons we can all take away from this. But maybe the most obvious and most important one is as above. Do not store the only copy of anything you care about on someone else’s computer and/or locked away behind an account you don’t have full control over. And if your content is riddled with DRM, well, even if you have a copy of it saved, it’s probably not going work.
Backup all the things. If you can’t afford more disk space - it’s very expensive right now - then even backing up to several different cloud services is a lot better than relying on one. And buy DRM-free where you can.
Sadly, the critical concerns highlighted by the Person of Interest TV show seem quaint in today's world
Around 15 years after receiving a recommendation for it, I’m finally working my way through the TV show “Person of Interest”. It is rather aligned to the paranoid side of my digital interests.
A big - the dominant underlying - theme of the show is digital surveillance.
One scene from season 3 episode 20 darkly amused me. A US senator is meeting a shadowy business man who wants to sell them a big fancy surveillance system they can use to - the classic excuse - locate terrorists, they named “Samaritan”. Of course for it to work properly it’ll need to suck as much confidential government data about US population and beyond as possible.
The Senator (spoiler alert) initially declines, stating with astonishment:
“You want me to give a private corporation access to the government feeds, to 300 million Americans; just so you can sell the information back to us?”
Coming now from the vantage point of today’s world: how cute, huh?
The era when that question is remotely rhetorical and the people in power have anything like that concern feels long gone.
I am of course talking about, amongst too many others, the likes of Palantir.
Famously, Palantir is traversing the globe offering governments exactly that deal. They provide surveillance analytics software such as “Foundry”, “Gotham”, “Apollo” and “AIP”. They expect governments to upload them confidential health, financial, intelligence, communications, crime, political, and sensitive national defence info - and that’s just the scope I’ve heard of so far.
They then will sell an analytical product derived from that back to us in order to, for example, identify targets for arrest, for deportation and so on, often using scammy “free first month” style marketing tactics aiming to lock governments permanently into their system irrespective of future massive price increases. The resemblance is uncanny. Except many governments don’t seem to feel that initial sense of increduilty the fictional senator does and so they’re signing up to it.
Palantir’s bizarre and dangerous CEO isn’t shy of the intent of some of this. It’s very Person of Interest, except without the secrecy.
“Palantir is here to disrupt…and, when it’s necessary, to scare our enemies and, on occasion, kill them.”
And some of the methods are very Big Brother thoughtcrimey.
A controversial US spy tech firm has landed a contract with UK police to develop a surveillance network that will incorporate data about citizens’ political opinions, philosophical beliefs, health records and other sensitive personal information.
…
Trade union membership, sexual orientation and race are among the other types of personal information being processed.
The excuse? Well, it depends on which arm of the state is paying this out-of-control extractive company for their wares, but in the above case it’s for the classic repeatedly-discredited “predictive policing”:
Crime records are combined with other intelligence sources such as financial information to create profiles of individuals including suspects and those “about to commit a criminal offence”, although Palantir denied its software was being used for predictive policing.
Palantir of course isn’t the only surveillance related company of concern. Flock “safety cameras” are being deployed throughout at least the US. People have many, many very fair concerns.
Originally it was sold as a private automatic license plate recognition system that sells access to its information on who is travelling where to any state or private business willing to pay. This system alone is enough to raise huge red flags. A private company collecting information on where and when everyone who owns or uses a care is travelling to is unlikely to be an optimum solution to anything and of course carries massive risk.
So-called “authorised” uses aside, already cases of users abusing the system have been found. 404 Media found several cases of police personnel abusing the system to, for instance, stalk potential or ex romantic partners.
For months during the summer of 2024, Jarmarus Brown, an Orange City, Florida police officer, ran his ex-girlfriend’s license plate through the Flock automated license plate reader (ALPR) system lookup database at least 69 times. He searched for the license plate belonging to her mom at least 24 times, and searched for the license plate belonging to her dad at least 15 times.
But it gets worse. Flock is collecting video, not number plates. It has added a special AI freetext mode where you can search for, well, whatever you want. Its own marketing materials show being asked to track someone with a “white shirt, navy hat”. As 404Media once again show “How Cops Use Flock to Track People, Not Cars” such as “female with Ugg boots”, “woman wearing grey shirt, blond hair, black shorts”. Apparently some search strings used include references to a target’s race or political affiliation.
One of its advertised selling points is it “integrates with LPR, gunshot and drone systems for seamless investigations”.
If for some unknown reason you feel OK with Flock videoing you wherever you go, well, as ever with this topic, one legitimate fear is that it’s not only them and their partners that will necessarily have access to their data. Rogue employees aside, they’ve already accidentally leaked “the reasons cops conducted searches, and sometimes the specific searched license plates” onto the public internet, as well as the live feeds from their cameras. Whoops.
Flock left livestreams and administrator control panels for at least 60 of its AI-enabled Condor cameras around the country exposed to the open internet, where anyone could watch them, download 30 days worth of video archive, and change settings, see log files, and run diagnostics.
Private Flock logins have also been exposed after their systems were infected by malware. A YouTuber has shown how easy it is for hackers to get sensitive data out of their cameras. It’s endless, and predictable.
Another private surveillance-feed-providing company is of course Ring, now unfortunately owned by Amazon. The public happily pays substantial money to buy camera-enabled doorbells and other devices. What the average person doesn’t seem to know is that their private footage can and has been accessed by authorities such as the police.
The BBC reports:
Amazon has been criticised for partnering with at least 200 law enforcement agencies to carry out surveillance via its Ring doorbells.
…
The bells send live video of customers' doorsteps to their smartphones, computers or Amazon Echo devices.
…
Motherboard says officers do not need a warrant to ask for footage or information.
“Amazon has found the perfect end-run around the democratic process,” Fight the Future said.
“These partnerships undermine our democratic process and basic civil liberties - they should be banned.”
Of course if your neighbour has one of these doorbells there’s really not a lot you can do about it.
These days the police should really ask you for access to your footage when they want it (as far as we know) but once they have it they can keep it and share it & your personal details with other orgs as they like. And:
Amazon coaches police on how to best talk residents into handing over their footage so police don’t have to get a warrant
And it’s clear that, technologically, they don’t need permission. Despite Amazon’s assurances to the contrary, Politico found that:
Amazon handed Ring video doorbell footage to police without owners’ permission at least 11 times so far this year — a figure that highlights the unfettered access the company is giving police to doorsteps across the country.
This footage is so useful to the state that in some places public money is given to Amazon in order to subsidise their purchase price or to have the police advertise them.
Lest you think that somehow Ring is only providing footage of murders to the police, it’s been noted that the police have requested that they provide footage of Black Lives Matter protests in the past.
Once again Ring cameras have security flaws. Multiple hacker groups have threatened them with release of their private data.
To be fair, this move to a ubiquitous surveillance system controlled by private interests is not without some public resistance. In the Person of Interest show there’s a radical privacy activist group called “Vigilance” who, it must be said, are known to use tactics rather more violent that I would condone, even whilst the concept of ensuring accountability amongst the facilitators of such systems is hard to argue.
The IRL groups I’m aware of do not tend to shoot people, but they exist, and you might consider joining one of them if the real-world state of this upsetting tech and policy development bothers you as it should. Here’s some links to get you started.
- Privacy International -"All Roads Lead to Palantir…how the data analytics company has embedded itself throughout the UK"
- Ring’s police partnerships must end, say more than 30 civil rights groups
- Medact’s Briefing: Concerns Regarding Palantir Technologies and NHS Data Systems
- Liberty’s campaigns around: UK police working with controversial tech giant Palantir on real-time surveillance network
- Get the Flock out
- The Nationwide Revolt Against Flock Safety Cameras
- Amnesty International: No Palantir in our NHS
- Good Law Project: Stop Palantir in the NHS
- Stop Palantir
- Stop Palantir taking over our public services! petition
- Open Rights Group
- Electronic Frontier Foundation
As you can see, there’s no shortage of groups with concern, which is great. There’s some rather obvious direct action I suppose one might feel inspired to do although it’s not without risk - e.g. Cities Are Covering Flock Cameras With Trash Bags. Although in that case it was city authorities themselves, not members of the public:
The city of Dayton, Ohio has covered its Flock automated license plate reader cameras with black trash bags in part because police there are unsure whether the cameras are still active and the city also doesn’t seem to know whether it is allowed to take the cameras down. The move comes after months of resident outrage, a scandal in which the city was sharing Flock camera data for immigration enforcement apparently on accident, and a $30,000 audit into how the cameras are being used.
We should not tolerate a world where the elected officials that run a public city are not sure whether they are “allowed” to take the cameras of a private company they don’t want surveilling their population down.
Buy a new monitor, get some adware for free
Plug in your nice new computer screen. Let Windows 11 do its thing. Enjoy seeing a load of software you didn’t ask for being installed leaving you with an indefinite future of seeing adverts for crappy antivirus software you don’t need whenever you use your machine.
Yes, LG and Alienware Monitors Are Trojan Horses, Auto-Installing Windows Adware.
Turns out Windows 11 has a feature that automatically installs associated software when you plug in a device. So, of course, device manufacturers are using it to make your computing life worse than it needs to be.
OEMs now treat companion apps as brand-experience platforms and ad-delivery channels - a pattern well documented among the worst tech scandals that have taken advantage of consumers. McAfee pop-ups arriving through a DisplayPort cable feel like getting a flyer shoved through a mail slot you didn’t know existed, and may leave you paying too much - in attention, data, and system resources - for hardware you already own.
Imagine if we’d designed world where turning on your computer didn’t feel like preparing for battle.
Donald Trump’s state department intends to allocate $12m to organisations in the UK founded by the prominent Conservatives Jacob Rees-Mogg and Toby Young, the Guardian can reveal.
I guess in some people’s mind it’s not considered meddling in foreign elections when you say you’re going to do it. Other more cynical types might suggest that at least other countries have the decency to do it quietly.
One can imagine the utter outrage that the MAGA types would feel if this was happening the other way around.
Respect democracy, sovereignty et al. Stay out of our elections.
Mysterious mushroom reliably induces lilliputian hallucinations
This is quite strange - it’s been discovered that a mushroom called Lanmaoa asiatica gives people hallucinogenic experiences if eaten uncooked. But they’re hallucinations are always of the same thing - and can last several days:
…anyone eating the mushroom needs to be careful because it also gives hallucinations of lots of tiny people about 2cm tall wearing brightly coloured clothes, all jumping, running, climbing and being generally playful, but in a normal, real-world setting.
More about thenfrom the Natural History Museum of Utah here:
A professor in Yunnan recounted how one evening during dinner (Jian shou qing is openly sold in markets and restaurants), he began seeing swirling shapes and colors after eating stir-fried mushrooms. Since the psychoactive effects are familiar to most locals, he began looking for xiao ren ren but was disappointed to find none – until he lifted the tablecloth and peeked underneath, seeing “hundreds of xiao ren ren, marching like soldiers.”
Even more curious, he said, “when I lifted the tablecloth higher, the heads came off and stuck to the bottom of the cloth and the bodies kept marching in place…
No one quite knows what substance in the mushroom is causing these effects, tho research is ongoing.
Also TIL: there’s apparently a known clinically defined psychiatric syndrome called lilliputian hallucinations - evidently named after the little people from the Gulliver’s Travels story.
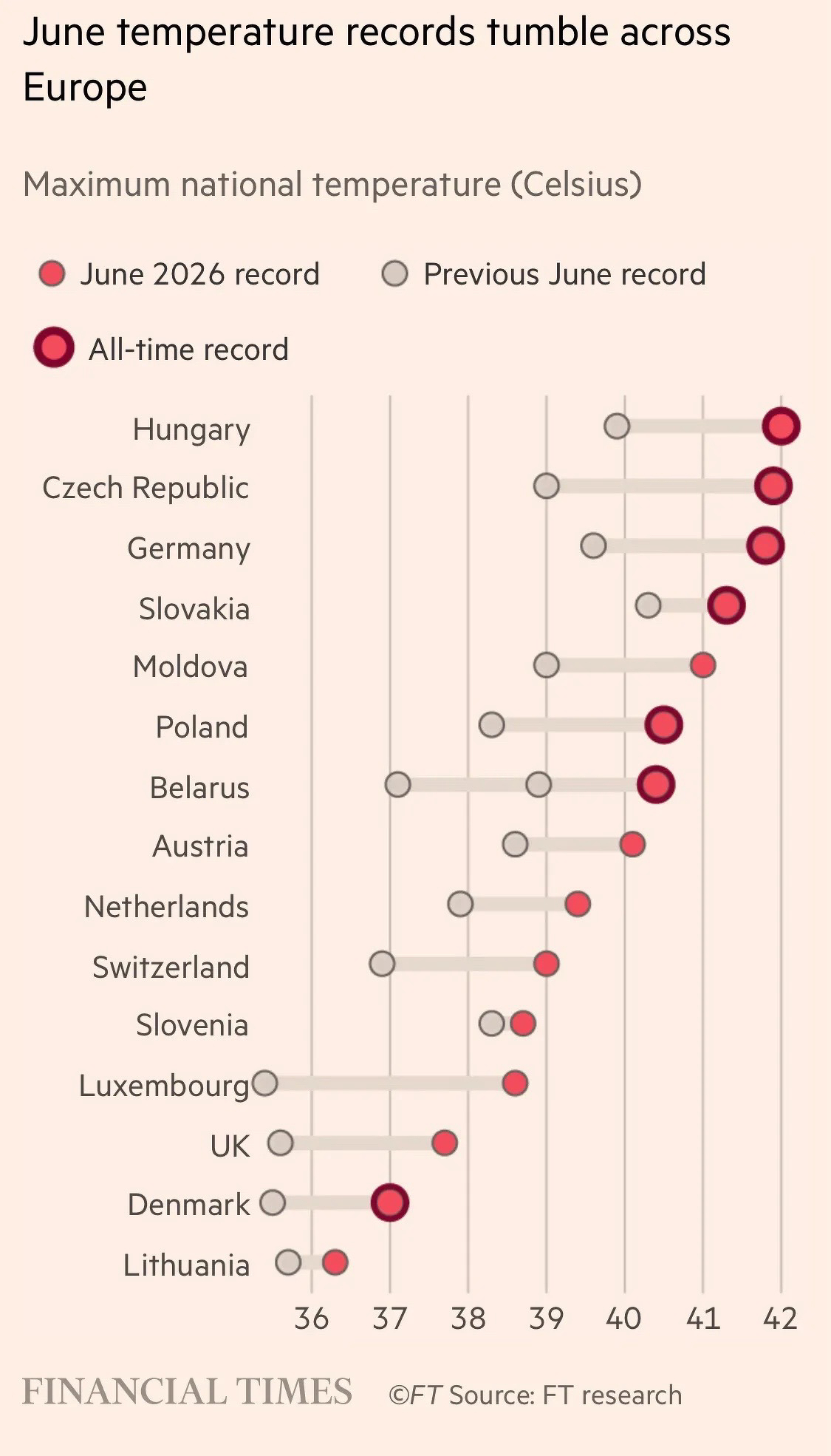
World records are being broken all over the place in recent times. And not in a good way.
The British people correctly identify Farage as being the sleaziest politician in the UK
Nigel Farage named sleaziest politician in UK in new poll - and even Reform voters think it
Sometimes the British public get it right!
Nigel Farage had been named the sleaziest politician in Britain, as questions over his undeclared donations continue to mount.
According to a new YouGov poll, 73 per cent of Britons think the Reform UK is sleazy, while 69 per cent of people say the same of his party.
Some 56 per cent categorised Mr Farage as “very sleazy”, with an additional 17 per cent finding him “fairly sleazy”, while 40 per cent of those who voted Reform at the last election today consider him to be sleazy
Not that our other party leaders get away Scot-free - but none of them are considered quite as sleazy and corrupt as the already-millionaire who secretly receives millions more pounds from foreign-living crypto barons and convicted fraudsters.
The polling highlights a clear gap between the public’s perception of Mr Farage and the other party leaders, with 51 per cent of Britons seeing Sir Keir Starmer as at least fairly sleazy, while 42 per cent said the same of Green leader Zack Polanski.
Meanwhile, only 36 per cent found the same of prime minister-in-waiting, Andy Burnham, and just 34 per cent found Tory leader Kemi Badenoch sleazy
The UK is currently undergoing its third heatwave in as many months. Given we have such a low prevalence of air conditioning (less than 5% of homes), everyone is desperately looking for solutions to the pain that is, amongst other things decimating our sleep.
June heatwave in UK led to ‘mass sleep deprivation’, poll suggests
And look, in today’s papers, a novel solution that has no downsides whatsoever!
Low-e windows keep homes cool…but may set neighbours’ property on fire
The Coming Storm plots the recent history of the modern day conspiracism that rots our politics today
📚 Finished reading The Coming Storm A Journey Into the Heart of the Conspiracy Machine by Gabriel Gatehouse.
As we all know, modern day politics, and much of the rest of life, has become laden with many often ludicrous conspiracy theories (only some of which turn out to be true).
In this book the author details his take on the history of how we got there in the world of US politics. He starts back in the 1990s where plenty of admittedly less popular theories surrounded President Bill Clinton and his wife Hilary, who of course would go on to be attacked with new ones of her own.
Remember the “Clinton body count” theory of the 1990s? Per Wikipedia:
The Clinton body count is a conspiracy theory centered around the belief that former U.S. President Bill Clinton and his wife, former U.S. Secretary of State Hillary Clinton, have secretly had their political opponents murdered, often made to look like suicides, totaling as many as 50 or more listed victims
Since then conspiracism has moved from the relative fringes to the mainstream of US politics. The book plots the path towards its modern-day culmination as enacted in the January 6th attack on the US Capitol.
Part of the route to brainrotting us all with such paranoia was dependent on recent technologies. Many emerged from internet trolls using message boards such as the infamous 4chan. The whole QAnon movement was one such example, starting off with a 2017 post on 4chan, which had huge impact. Q believers were amongst those who stormed the Captiol.
Arguably at least the more outlandish theories often started off as tongue-in-cheek shitposts but somehow developed such that a vast amount of Americans (and of course other folk, but this book focuses on Americans) believe them to reflect reality. Or at least enough to claim to believe them and take action on them.
Then we have the big social networks who even today are vast conduits of these weird and oftentimes dangerous ideas. One serious problem is that the likes of Facebook, Twitter et al do very little to stop the spread of even the most obvious disinformation. That’s largely because we have allowed a world to develop financial incentives are for them to in fact encourage these emotion-provoking engagement-provoking and hence money-making posts. Mark Zuckerberg gets richer the more we argue about whether the Earth is flat or Hilary Clinton eats babies.
The author, correctly in my view, argues that all this disinformation is not just a waste of time but in fact results in a weakening of trust - in each other, the media, politicians and more - and concomitant weakening of democracies.
A certain type of politician throws petrol onto the fire, doing nothing but encouraging these movements - again because the incentives are there for them to do so.
The book is surely very relevant, and very scary, from an author who has spent a good few years pursuing the subject.

Converting between music file formats with ffmpeg
ffmpeg is a much venerated tool for doing most anything in the world of fiddling around with audio and video files on one’s computer. To let it describe itself:
FFmpeg is the leading multimedia framework, able to decode, encode, transcode, mux, demux, stream, filter and play pretty much anything that humans and machines have created. It supports the most obscure ancient formats up to the cutting edge. No matter if they were designed by some standards committee, the community or a corporation.
It also works on Linux, Windows, MacOS and a few other platforms you probably aren’t using. There are slightly less official ways to use it on iOS (e.g. via a-Shell) and Android (e.g. via Termux)
So far my main use-case has been to convert between music file formats. For future referenece, this is how one can convert a song from flac format to, in this case, MP3 V0. Sure you in theory lose some quality converting lossless to lossy, but the way I listen to music it really isn’t very noticable and it dramtaically saves diskspace. One example file I used went from 42mb to 8mb.
It’s simple. First install ffmpeg. On Linux that’s:
sudo apt install ffmpeg
Then you can convert a flac to a variable bit rate (VBR) MP3 (amongst a massive variety of other formats) in the following way:
ffmpeg -i your_music_file.flac -c:a libmp3lame -q:a 0 your_music_file.mp3
The -c parameter is the encoder you want to use, in this case one for MP3s.
-q refers to the audio quality. The 0 setting is the highest quality for a (VBR) MP3 but slowest to run. But it took virtually no time at all for me.
If you prefer a fixed rate MP3, e.g. 320kps, you can use the -b parameter instead of -c like:
ffmpeg -i your_music_file.flac -c:a libmp3lame -b:a 320k your_music_file.mp3
If you want to convert all flacs in a folder to MP3s at once then you can use standard Linux CLI stuff, e.g. the below for the VBR option.
for f in *.flac; do ffmpeg -i "$f" -c:a libmp3lame -q:a 0 "${f%.flac}.mp3"; done
There are innumerable other parameters for different file formats or different options. The official documentation is one place to go to learn about them all.
Cryptomator is on a half price sale should anyone want a copy, or to support a worthy project on the (relatively) cheap.
It’s an excellent open-source solution, recommended by PrivacyGuides amongst others, allowing you to easily encrypt your files in a way that’s very compatible with the use of cloud drives.
This means that Google, Microsoft or whoever you cloud with - or anyone that works for them, or any one who hacks them - cannot see the contents of your files. I would not put any sensitive file on such a drive without an application like this.
The desktop software - which is available on most platforms - is basically entirely free always. You can financially support it if you see value.
The phone apps usually cost around $30 if you want to enable full write capabilities but are on sale for a while. If you can afford the $30, or more, then I’m sure they’d appreciate it at RRP; it’s a project that highly deserves funding. If $15 is your limit, go get it now!
The USA's 250th birthday party echoes its 150th in unfortunate ways
Happy 250th Birthday to the modern incarnation of the United States.
There is nothing new under the sun. The Guardian highlights fairly chilling parallels between the darker side of this weekend’s celebrations as convened under the current venal, fragile, egoist, hate-filled figurehead of their current administration and those seen in the equivalent occasion one hundred years ago:
The closest anniversary parallel, according to McKean, may actually be a full century ago, in 1926, a year when the US marked its 150th birthday and which also saw 15,000 white-robed Ku Klux Klan members march down Pennsylvania Avenue to the White House, while a nativism redolent of Trump’s “America first” rhetoric stalked the land.
“We had just gone through a major pandemic with the Spanish flu, which had killed millions of people worldwide, not dissimilar from Covid,” said McKean. “There was also this huge sort of inequality happening in America at the time. Immigration was a big issue, and laws had been passed and signed by [then president] Calvin Coolidge to impose quotas on each country that had had immigrants coming to this country.”
Photographs like this do nothing to ease the mind:

That motley bunch of cosplay paranoid weirdos are members of Patriot Front, a Neo-Fascist group who, to quote the article, facilitated a shameful event where ‘hundreds of masked members of the white supremacist organization marched and chanted in the US capital’; shaming their country on what could and should have been a celebration of how far their nation has progressed.
This photograph strikes me as being truly one for the ages.

Nearly 300k more people in England may die over the next decade as a result of the US UK trade deal
US-UK drug deal could result in 229,000 excess deaths in England, analysis suggests.
This is because the deal entails us having to pay 25% more for drugs than we do at present for the next decade at least. Ergo the NHS is to divert a cumulative £45 billion (!!) over 10 years from other essential services to do so.
This means that:
Reduced NHS spending on services will have an adverse effect on the nation’s public health, the analysis found, causing 229,000 excess deaths by 2036
For context:
The estimated avoidable death toll is larger than the number that occurred during the Covid-19 pandemic, between March 2020 and June 2022 (137,000)
The deaths include yet further to an estimated 291,000 if one includes indirect deaths due to changes in adult social care, which of course we should.
📺 Watched Industry.
Here we follow the lives of a group of ambitious and mostly new-to-it investment bankers and traders as they enter the still-brutal banking industry some time after the massive 2008 market crash. Some of it is financial drama, something I find myself strangely attracted to despite the cruel destruction the real thing has overall wreaked upon the world. A lot of it is lifestyle drama - sex, drugs, maybe some rock ‘n’ roll.
There are no heroes here. The first series really starts off with a young lady who has lied her way into getting a job in the first place. The ethics don’t really improve from there as everyone lives or dies - mostly metaphorically - by whether they can make more money for their employer than their peers.
As the seasons move on, the plot felt like it focused on the day-to-day work life of these under-pressure yet unfathomably rich wannabe bankers and more on the surrounding antics of the players in question. Nonetheless, whilst it’s “entirely” fictional, some of even the bizarre later events I believe are echos of what we know to have happened in the real world. For example, the meeting of a bunch of the very wealthy and very racist multi-millionaires for a lovely dinner? It’s hard not to see this as a direct parallel to, for instance, Peter Thiel’s various dinner parties involving the rich and influential ruiners of today’s world.
In fact, as I often think with these “fictional but obviously not entirely so” programs, I wish they’d done a documentary after the fact of which real life events may have inspired which story-lines. I think anyone sensible with less of a compulsive news fixation than myself might have been surprised, as I imagine I would be.
I was somewhat darkly amused to see the Office for National Statistics complained that it unfairly represented their employees in a damaging way. Without spoiling the storyline perhaps they do have a plausible reason to do so, although I’d be surprised if the damage was all that damaging.
But it has been noted elsewhere that perhaps the banking industry might have more cause for complaint:
Simon French, the chief economist at the investment bank Panmure Liberum, said: “If that is Darren’s major issue with Industry, he has been focusing on the wrong bits … Can I write a letter saying that City workers are worried that BBC is portraying us all as sex-mad, drug-peddling sociopaths?”
That said, the stories a friend of mine who worked in the investment banking industry once told me might suggest that there really is little that could be really be described as libellous there.

📺 Watched Under Salt Marsh.
This is a 6-episode crime drama set in a small and isolated community in Wales that’s in impending risk of destruction by rising sea levels and other aspects of the IRL climate catastrophe.
Currently a school teacher, former detective - the “former” part of that being the choice of her superiors rather than herself following an earlier conflict- Jackie tragically lost her niece a few years ago. Lost in the sense of “inexplicably went missing”.
A few years later, another school child unfortunately turns up dead, seemingly drowned in a ditch. But are things as “simple” as that? Well, obviously not given there’s 6 episodes of atmospheric, gloomy but compelling detective work by someone who isn’t actually allowed to be a detective any more, racing against time before the evidence is erased by the incoming evacuation-level storm.

🎥 Watched The Apprentice.
Why do I do it to myself one might fairly ask? But I did.
This is the story of Donald Trump’s early years in 1970s-80s New York. It is nearly as full of the misogyny, racism, greed, arrogance and incompetence that shaped his bizarre success as one might imagine. The main narrative seems to be around how his relationship with the famously aggressive lawyer Roy Cohn aided his rise and shaped his business and political “style” for want of a better word. A bit of Trump’s family life is portrayed, again providing clues as to how he turned out like he did.
It’s full of foreshadowing of what came next, although the story cuts off just as he (well, a journalist, Tony Schwartz) is writing his book - I assume the “Art of the Deal”. That’s the book Trump says is his second favourite book ever, modestly demurring to the Bible as the first. Schwartz on the other hand later said being involved with it was the greatest regret of his life and that Trump was not in the least bit involved in writing it.
The mannerisms and speech patterns of the actor playing Trump are certainly enough to bring shudders to anyone who has had the displeasure of hearing him speak in person.
Roy Cohn in the real world is certainly a character worth learning about to help understand how we got to where we are today. The BBC has a rundown of the guy here:
A Washington Post article about Cohn’s influence, published during the 2016 presidential campaign, had the headline “The man who showed Donald Trump how to exploit power and instill fear”, and summed up his lesson as “a simple formula: attack, counterattack and never apologise”. Cohn was also expert at media manipulation.

Read Andy Burnham and Steve Rotheram's 10-point manifesto for a better Britain in their 2024 book 'Head North'
📚 Finished reading Head North A Rallying Cry for a More Equal Britain by Andy Burnham and Steve Rotheram.
Having recently won a by-election by a very impressive amount, it seems that Andy Burnham is almost certainly going to be the next Prime Minister of the UK. With that in mind, I set to reading the book he co-authored a couple of years ago whilst he was the mayor of Manchester alongside his colleague Steve Rotheram, mayor of the relatively nearby Liverpool City Region.
The first section of the book is mostly memoir style for both of them. Each author writes a few paragraphs and then the other takes over for a while, identified by the font. Helpfully, their journeys and opinions are not dissimilar. Interestingly, both of them seem to have been (quite fairly) “radicalised” into politics by the corrupt state cover-up of the Hillsborough stadium disaster back in 1989. It was not until nearly 30 years later that, the truth having finally been revealed and accepted by most, anyone was charged with an offence.
Burnham was, famously, an MP in the past. Much of this book is about why the Westminster system is basically corrupt, or at least designed in such a way that actually getting something done to further the goals of the authors - most notably to address the vast inequality between the relatively wealthy city of London and the deprived areas of the north (hence the title…) is absolutely impossible. The seemingly unmodifiable method the government uses to judge the worthiness of new investment, in their eyes, is guaranteed to favour well-off areas every time. And the whole Westminster voting, whipping, etc. system means that even the best intentioned of MPs ends up supporting stuff they vehemently disagree with or is against the interests of the constituents they are supposed to represent. In many ways, the authors' views on Parliamentary-adjacent practice are at times rather in line with former MP Rory Stewart’s.
Eventually Burnham tired of the futility of it all and became instead the mayor of Greater Manchester. He found this position, with its tie to a specific place, to be a much more effective conduit for change, albeit still frequently having to battle central government naysayers. It is thus quite interesting to me how he reconciles his masterful effort to return to Westminster with this. All I can think is that he believes that now he is very likely to be in a position of great power, he can burn down the system and build up something just and effective. Best of luck to him.
In the second half of the book the two authors present their joint manifesto for change. Perhaps it’s worth enumerating it here given one of them is likely to be ruling the country fairly soon. There are ten points to it:
- Britain should have a written constitution - a single legally binding document to protect the rights of citizens and limit governmental power.
- The introduction of a “basic law”. This would be a statute that protects our core rights and protects democracy, designed in a way that any given Parliament of the day could not override. Germany has something like this already. Burnham and Rotheram think a big component of this should be a requirement guaranteeing citizens equal life chances irrespective of where in the UK they are born or live.
- Reform of the voting system: No more first-past-the-post. Switch to some variation of proportional representation.
- Abolish the whipping system in Parliament so MPs can actually choose how to vote themselves.
- Replace the House of Lords with an elected second chamber that is guaranteed to represent all of England’s regions. Something more like the US Senate I suppose.
- More devolution. Similar to the situation with Scotland and Wales, devolve as many powers as possible to England’s cities and regions. Let local mayors make local decisions.
- Reform education so both vocational and academic routes are equally funded and respected.
- A Grenfell law - legislate for and thoroughly enforce building safety standards. There should be corporate accountability and criminal liability for those who do not adhere to them.
- A Hillsborough law - this has two aspects in their view. First, make it illegal for police and other public servants to lie about public disasters. Yes, it is kind of incredible that this isn’t already the case, but apparently it isn’t. Secondly, ensure parity of legal funding for bereaved families bringing court cases against public bodies in these situations. It is clearly unjust for the government to win cases simply because they can afford more expensive lawyers (with public money).
- Use Net Zero to re-industrialise the north. The clean energy revolution we so desperately, desperately need could be an avenue for re-introducing good, well-paid manufacturing and other jobs into the areas of Northern England currently plagued with a lack of quality jobs.
OK, there’s not too much I’d argue against there. I await with a mix of excitement, but perhaps more trepidation, to see what Burnham can do about the above, in the very likely case that he will soon be the leader of the Labour party with, to be fair, a very large majority at present.

Patriot: the memoirs of the incredibly brave Russian anti-corruption campaigner, Alexei Navalny
📚 Finished listening to Patriot by Alexei Navalny.
This is the incredibly brave political campaigner Alexei Navalny’s (tragically posthumous) memoir.
Navalny was an unimaginably brave anti-corruption campaigner who wanted to see the freeing of Russia from the cruel and kleptocratic regime of Putin et al. He is perhaps most famous for the YouTube documentary-style videos his organisation created to reveal the hypocrisy and corruption of the Russian political elites as well as call for a popular uprising to liberate Russia from this gang of criminals who he saw as, apart from anything else, ruining Russia’s chance to become a successful and happy country. That said, along the way, we learn that making videos was far from his first choice of activity. It’s just what he found broke through the most.
Famously, back in 2020, he was poisoned with Novichok, and nearly died, via a criminal act facilitated by the Russian state. Thankfully, his life was saved in Germany. And he no doubt could have stayed there with his family and continued his campaigning remotely if he wanted to. But he most certainly did not want to.
In the book he makes it clear that he wanted to lead by example. He does not want everyday Russians to act in fear of Putin’s state, and so he made himself act as though he didn’t either (it may not have been an act, certainly later on he enumerates the ways he found to avoid the fear at the darkest points in his journey). So he returned, with his equally courageous and supportive wife Yulia, to his homeland. Inevitably he was immediately captured and imprisoned, and was stuck there for years, in increasingly cruel and punishing jails.
Much of the book is thus a prison diary, interspersed with a few of his Instagram posts over the years. However he tells of even the dourest of events with incredible humour; wit and irony abound. He’s an incredibly likeable character, perhaps amongst the best of what humanity has to offer.
Whilst he’s almost entirely locked away, invisible to the outer world, the regime throw more and more allegations of new crimes against him, ramp the level of his punishment up and up - and yet still in no way does he give in.
When he is able to convey some sort of message to the outer world, it’s always to thank his many supporters for their efforts and implore anyone subject to Putin’s state to fight back, to never be afraid, to never stop highlighting the cruelty and hypocrisy of their government, and above everything else, to never let go of the idea that Russia could be a truly happy and successful country if only it was led by a less greedy, cruel and criminal government.
Of course recent events don’t necessarily suggest that that day is particularly near. And when the day eventually comes sad to say, Navalny will not be around to see what one has to hope will be a marvellous enactment of his vision at some point in the future, having, since writing the book, died of “natural causes” / in very suspicious circumstances whilst jailed within a Siberian penal colony, at the age of 47.
His brave widow, Yulia Navalnaya, herself an avid campaigner, convinced that her husband was murdered with poison, continues the fight. She’s now the head of the Anti-Corruption Foundation that Alexei founded as well as the chair of the Human Rights Foundation. Godspeed.
