Anthropic’s AI Claude hacked into three organizations during cybersecurity test
Recently I read:
Drifting SpaceX rocket heading for accidental collision with moon
The tangled financial web at the heart of Reform UK: ‘Sources have described how staff at several different banks were so concerned about a range of transactions…that they reported them to the National Crime Agency’.
Latest posts:
📚 Finished reading The Compound by Aisling Rawle.
Imagine the show Love Island, except with fewer limitations, worse incentives and set in an isolated desert compound in world that is at least, outside of the compound, somewhat dystopian. A bunch of beautiful people go into the house and may stay as long as they both share a bed with someone else each night and are not the worst at completing deliberately manipulative challenges.
Challenges bring increasingly luxurious rewards which you may keep forever, an unimaginable boon in a world where the average person can do no more than struggle day-in-day-out to get by in what’s left of the world. If you win you can stay in the house as long as you like, protected from the outer world.
So it’s basically a slightly less moral version of Love Island set in a slightly more dystopian world than we live in. i.e. highly compelling, and probably a foreshadowing of what we’ll all be watching in a couple of years.

In further ‘if you can’t download and back your digital content up in a DRM free manner then you don’t really own it’ news, Sony is deleting over 500 movies from people’s PlayStation libraries. Films they bought for money. No refunds available.
Learned a new word today: Kakistocracy
…government by the worst, least qualified, or most unscrupulous people
I’m sure I’m going to be using it daily.
Turns out it was the Economist’s word of the year in 2024.
Some good context from George Eaton:
Reform have now lost six by-elections in a row in England, Scotland and Wales.
Their national poll rating is 26% – below Labour in 1983 – and Farage’s approval rating is -37.
They’re very far from the voice of the people and need to stop being treated as such.
Labour's Andy Burnham wins Makerfield election by ~9000 votes
Finally a surprisingly good-news election result here in the UK.
This is of course also potentially the entrance of our next Prime Minister, tbd.
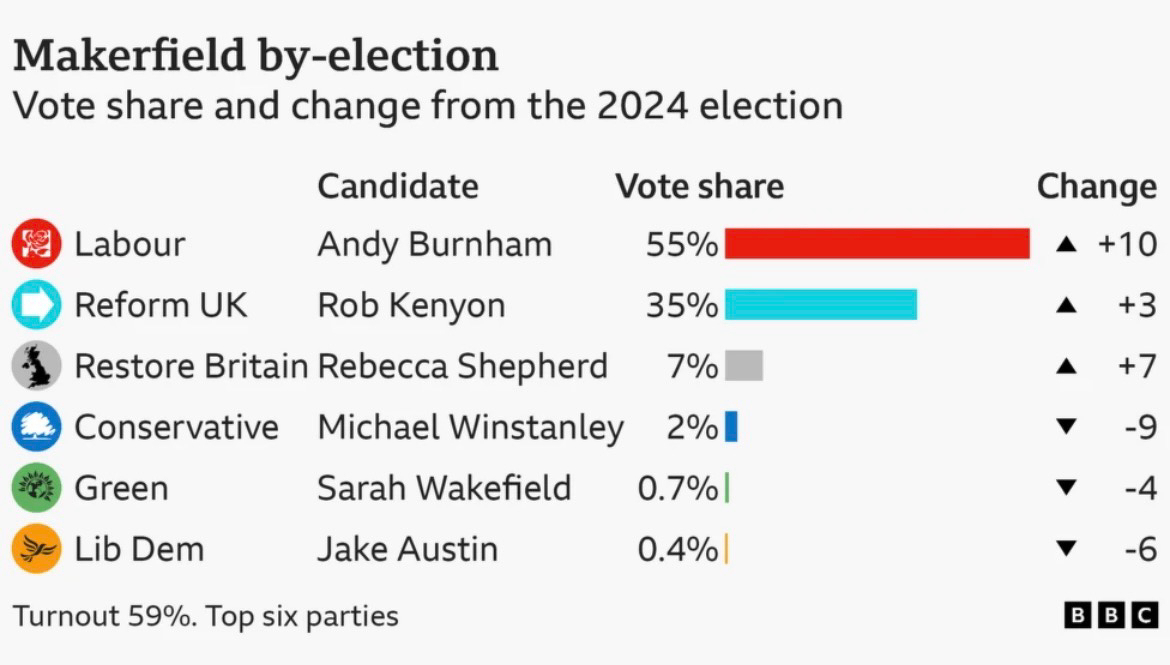
The scale of the victory is impressive. To be honest I was hoping/expecting Burnham would win but only on the basis of the despicable Restore party attracting the votes of the most hate-ridden Tommy-Robinson-pilled of the potential Reform UK vote. But here Labour attracted over 6000 more votes than those two horror shows combined.
Sure, there was a huge ground game with every potential voter’s door apparently being knocked on 6-7 times by various levels of Labour campaigners, including plenty of fellow MPs. There was a concern that it was so intense that’d it end up actually annoying the voters. That’s not obviously not sustainable for a General Election.
I don’t know how much that affected the the vote. But the point is, it can be done.
Explaining Social Deviance is a 10 part run-through of answers to 'what makes something deviant?'
📚 Finished reading Explaining Social Deviance by Paul Root Wolpe.
This is really a series of lectures and PDF notes. I’ve enjoyed the series before and at some point I watched enough Criminal Minds that I decided that I too needed to virtually join the fake FBI team and understand all about causes “deviance”.
This series isn’t quite that, but rather an examination of the critical question of what the category of “deviant” even means.
Over the centuries “deviance “has been defined in very different ways by different people with a wide range of consequences. Perhaps fairly obviously, there’s no right answer, or at least no obviously objectively right answer. When formulating our own views we should always examine why something is considered deviant and who benefits from that classification.
This audio-and-text then seeks to educate us about some of the theories that humankind has come up with over the years, which is an equally fascinating topic.
Here’s a quick list of the theories covered, or at least the ones I remembered. Many are of course incompatible with each other:
- Demonism: deviance is caused by dark supernatural forces; some people are just evil. Demonic possession would be an obvious example.
- Pathology: deviance should be thought of as an illness. To put it bluntly, some people get illnesses that make them deviants.
- Social disorganisation: deviance isn’t conditional on the individual. Rather it increases when communities lack stability, control and order.
- Functionalism and anomie: deviance is natural and can be useful to us. And if society sets us goals but blocks conventional means to achieve them then that strain can lead to deviant behaviour.
- Learning theory: we learn deviance via interacting with other people and acquiring some of their attributes.
- Control theory: deviance is our natural way. Instead we should be asking what makes us not deviants? It’s conformity that is learned from social bonds, fear of punishment etc.
- Labelling theory: nothing is inherently “deviant”. It’s only how people label any given act that makes it so. The whole thing is a social construct and subject to change.
- Conflict theory: the powerful strata of society determines what is “deviant” in order to defend their own interests.
- Constructionism: the similar idea that deviance is constructed via discussion and rule-making.
I’m a big fan of the Big Theory genre. This added, or at least refreshed, a few to my mental repertoire.

Unsurprisingly the Online Safety Act hasn't stopped social media companies pushing dangerous content
In case anyone was in danger of thinking that the Online Safety Act has solved the harms caused by the big social media platforms:
Nearly half of girls and a third of all teenagers saw suicide, self-harm and eating disorder content on social media in a week, a study shows.
(Source)
Or:
X has refused to take down dozens of social media posts reported as “hate, abuse or harassment” in which prominent UK politicians, including Kemi Badenoch], have been racially abused.
In May, researchers from the social inclusion thinktank British Future reported 30 posts from this year in which the Conservative party leader was called the N-word. In each case the researchers used the platform’s “hate, abuse or harassment” reporting option. X refused to act in the majority of cases, despite repeated requests
(Source)
It remains astonishing that some of these platforms are allowed to exist in their current form. I mean, our government, including the politicians specifically being regularly abused, continues to use X for official communications.
The Trump administration forces Anthropic to stop foreign nationals accessing its latest AI models
Yet more real life evidence as to why digital sovereignty is a critical issue.
Last week Anthropic gave access to its latest AI models - Fable and Mythos - to anyone who wants to pay for it, my employer included.
Yesterday the apparently anti-freedom vengeful scared little snowflakes in the US government decreed that Anthropic, a private company, must ban non-American citizens from using it. And so they have.
I imagine this product is too new for very many people to have introduced a real dependency on it. And there’s plenty of people who would be anti its use, anti its existence, for other good reasons.
But if the model is either good enough that it provides substantive new power to its users, and/or this same type of arbitrary legislation is used on some other more mainstream technologies, well, a big chunk of the globe may feel the pain.
After all, if US was to shut off just all of its big AI models to the world, well, I think a concerning number of businesses and governments would face some real obstacles - to a large extent predictable ones of their own making. And that’s just AI, a relatively small part of our overall technological dependence on US tech.
If this stuff is really as powerful and critical as it is claimed, it’s very obviously the height of irresponsibility to allow a handful of extraordinarily rich private companies who are subordinate to the rule of a couple of unfriendly governments to have a monopoly on it.
Dark Mirror retells the Edward Snowden story from a journalist's viewpoint
📚 Finished reading Dark Mirror by Barton Gellman.
This is a 2020 re-telling of the (in)famous story of Edward Snowden and the leaks of NSA material he provided that made real the degree and methods of US government spying on its own citizens, as well as the rest of us.
This was where we learned the details of the NSA’s easy access to and storage of your email, photos, messages, your physical location via mobile phone cell towers, as well as all sorts of other extremely dystopian, extremely abusable and potentially illegal material.
Remember PRISM et al? As revealed to us by a trove of horribly-designed top secret powerpoints.

The author here, Gellman, is one of the journalists that originally worked on reporting the story after Snowden approached him, at first under his covert identity as “Verax”.
Whilst I’ve read countless articles over the years as well as Snowden’s autobiography, I very much appreciated the tale from the journalist’s point of view. Understanding the process of the approach, Gellman’s efforts to understand whether he was for real or simply an internet weirdo, as well as how he thought about the tension between reporting extremely important truths vs revealing state secrets that were potentially of benefit to the US’s enemies provides a vantage point distinct from Snowden’s own. Gellman also had to consider his own safety, threats of both legal action and having his own computer targeted for hacking included. After all Gellman has seen, and stored, documents most of us will probably never see even after the main revelations have been reported on.
Whilst the book is perfectly readable by someone with no interest in or knowledge about tech, I did enjoy him providing a handful of the Linux commands he used to explore the vast amounts of files in the leak.
He presents Snowden as a complex character. Often people either believe he’s a white-knight hero striking back against the illegal acts of his government, or a traitorous evil-doer who hates America. Being human, he clearly isn’t entirely either. There was plenty of tension and uncertainty between the parties involved at times. I personally lean towards the hero side. Reading this book provided an important reminder that if you truly want your data to remain private, unfortunately it is incumbent on you to figure out the appropriate tools and services that will present the most challenge to any wannabe spies, state or otherwise.
Of course most of us will not become specific targets of the state, but the point of the revelations was that that doesn’t matter. They’re collecting and your information anyway and running analysis over vast swathes of it. I am especially uncomfortable about that given the nature of some of the world’s governments at present.

DocFetcher is a great multi-OS application for searching through vast tranches of your files
DocFetcher is a free and open source application available for Windows, Linux and macOS operating systems that lets you search the contents of the files you have on your computer. What’s great about it is its search speed and comprehensiveness. You have to let it build an index of the files you want it to search, but once that’s done you can search through massive hauls of any compatible docs.
I tried it out on the whopping archive of Epstein related files the US Government released a while ago - vast number of large PDFs, hundred of gigabytes - and it worked a treat. Indexing them took ages, best left overnight, or over several nights. But the resulting search was perfectly fast and comprehensive enough for interactive use.
Here’s a screenshot from its official site:
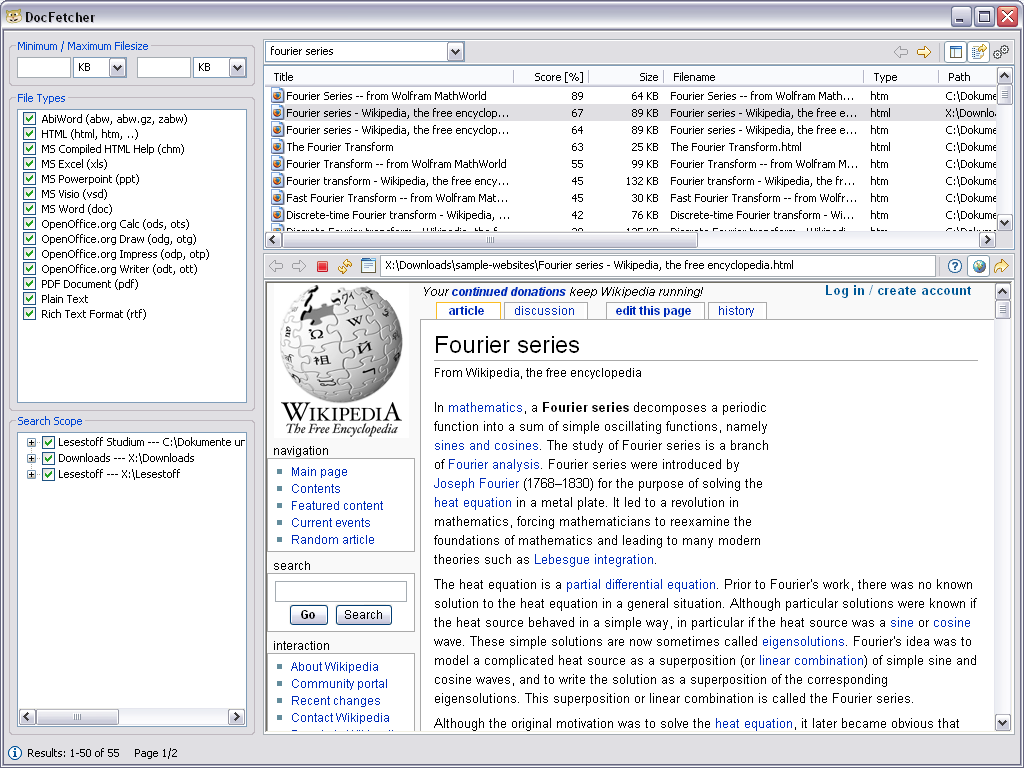
It can search through a wide variety of files. To quote:
- Microsoft Office (doc, xls, ppt)
- Microsoft Office 2007 and newer (docx, xlsx, pptx, docm, xlsm, pptm)
- Microsoft Outlook (pst)
- OpenOffice.org (odt, ods, odg, odp, ott, ots, otg, otp)
- Portable Document Format (pdf)
- EPUB (epub)
- HTML (html, xhtml, …)
- TXT and other plain text formats (customizable)
- Rich Text Format (rtf)
- AbiWord (abw, abw.gz, zabw)
- Microsoft Compiled HTML Help (chm)
- MP3 Metadata (mp3)
- FLAC Metadata (flac)
- JPEG Exif Metadata (jpg, jpeg)
- Microsoft Visio (vsd)
- Scalable Vector Graphics (svg)
I also enjoy that the first point the creator mentions when discussing their design philosophy is that it is “crap free”.
It’s potentially marginally less friendly to set up than some applications that claim to do similar things. But an average user should get on with it well. You will need a bit of extra disk space for the index which can be of substantial size, but obviously still substantially smaller than the source files you’re searching. The resulting search speed and scope is well worth the indexing, as is the way it immediately shows a snippet of the actual line in the document where your search term is found to give you the context up front.
The one slightly fiddly thing I did adjust in my version was the amount of RAM it is permitted to allow. By default it’ll only use some relatively small amount, I forget whether it was 512mb or 1gb. But there are ways to configure it to use much more. I think I upped it to 4 or 8gb when testing indexing the big tranche of Epstein files. The in-app doc tells you how - it’s basically either overwriting one file with another or editing a configuration file.
Once indexed, the search syntax comes from Apache Lucene, which means as well as simple Google-style searches (“dog”, “dog OR cat”) you can come up with constructs like “words similar to dog”, “dog but it needs to be within 10 words of cat” or “the document title should contain dog or cat but dog is more important”. The software’s documentation on this is here, and the Apache Lucene docs themselves are here.
The free version of the software is considered “legacy” and no longer updated. However, it still works just fine on modern operating systems. There is a newer closed-source “pro” version of the software should you need a more or more up-to-date features or just want to financially support the software - although I have found the free version features perfectly fine for my use cases.
The Pro version has apparently got better text extraction abilities though so I would consider it for any project for which that would be important. It’s a one-time cost of 40 euros which I think is perfectly reasonable for folk in a position to pay.
On the grimmer side of Wikipedia entries I see there’s now an official page for ‘Deaths linked to chatbots’. It’s much more up-to-date than my motley collection of these tragedies.
One of its sources is llmdeathcount.com, a site that no one can argue has a misleading URL.
The economic benefits of Open Source software
Continuing to make my way through the Open Rights Group’s important report on Digital Sovereignty. Their (and my!) preferred solution involves moving systems over to open source technologies, or, if suitable candidates don’t exist, then creating new technologies that are open source from the start.
The key advantages that following this path would provide I think exist in domains far beyond the financial. It would be urgently worth doing even if it cost significant money. But it’s nice to see some figures collected which suggest that such a move could in fact support local economic growth. That was, after all, the one true key sole priority of our current government not so long ago, for better or worse.
From p19 of the report:
• Greater investment in Open Source can also drive UK economic growth, supporting domestic innovation and a more competitive technology sector.
• Despite underpinning much of the global digital economy, Open Source remains underrecognised in UK government strategy.
• National economies would be 2–3% smaller without Open Source software.
• Open Source is present in over 95% of proprietary software systems, making up around 70% of their codebase on average.
• EU research suggests every £1 invested in Open Source returns around £4 in economic value.
• The Linux Foundation estimates 2–5x return on investment for organisations contributing to Open Source, rising to around 6x for leading contributors.
• France’s government preference for Open Source procurement helped generate 9–18% annual growth in IT startups, while also creating globally valuable Open Source assets.
• In the UK, OpenUK estimates Open Source contributes around £13 billion annually, representing 27% of the technology sector.
• A 2024 Harvard study estimates the global demand-side value of Open Source at $8.8 trillion, noting firms would need to spend 3.5x more on software without it.
• European Commission research suggests a 10% increase in Open Source contributions could add 0.4–0.6% to annual European economic growth
Evidence-based investing guidance from Tim Hale's book 'Smarter Investing'
📚 Finished reading Smarter Investing: Simpler Decisions for Better Results by Tim Hale.
This is the fourth edition of Smarter Investing. It was actually one of the older editions that helped me get going on the pro-investing path back in the day. But since then, temptation has on occasion led me off the Hale path. Nothing disastrous ensued, but nonetheless I figured it’s time to give it another read. Besides, a lot has happened in the world since the first edition
The book was revised in 2023 so of course it doesn’t contain direct reference to the absolute chaotic insanity in the world of economics that we see in very recent times. It knows what a Bitcoin is (his advice: avoid) but it doesn’t know that a tariff-obsessed corrupt baby is in charge of the free world (my advice: avoid).
However, the whole point of the book is: don’t worry about it. Just keep doing the same thing when it comes to investing, and you will - assuming you are not very unlucky - come out on top.
In sum, the idea is that instead of making your own dodgy stock picks and/or paying an advisor to ruin your fortune, you should instead build a low-cost diversified portfolio that is in line with your appetite for risk. Rebalance it now and then so it keeps doing what you want it to. Repeat forever. No new decisions needed. Wait a while. Retire richer than you’d otherwise have been.
Why is this the method of choice? The book contains a lot of evidence around how even the average professional stockpicker returns less profit than the market average, so what chance have I, an uninformed pleb, to do better? Instead, we should use historical evidence to understand the general direction of various markets and their correlates.
The book also goes into the psychology of investing which is where people apparently tend to go wrong. Your worst enemy is: you. Yes, it’s You that tempts you into buying things high and selling them low.
The real practical side of the book is its clear and illuminating guide as to what components your portfolio should consist of, as well as suggesting some funds and ETFs that you might consider for each component.
It can be nearly as simple as you want. Below I’ll pop what I take to be his favoured breakdown of investment components - but he seems open to simplifying it if it seems a lot. Just buying 1 cheap fund to represent “all stocks” and another to represent “bonds” is perfectly compatible with his mindset, and a lot better than what most people do.
But if you want to go all-out Hale, this is what he’s driving at. The risk rating increases as you go up with respect to the “return engine assets”. You pick a column that suits you riskwise and go with that.
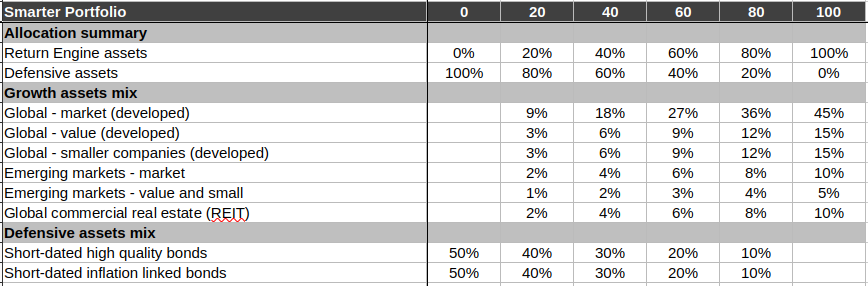
To over-simplify, the “Smarter Portfolio 20” column means you’ve got a 20:80 split between high-performing-but-riskier equity and low-performing-but-less-risky bonds.
But to understand why and how we get to the numbers above, and how to actually go ahead and create the requisite portfolio, you should definitely read the book. It’s not even particularly heavy going. Oh, and I transcribed the numbers in the table above myself, so also it’d be wise to get your hands on the book to double-check I did that correctly.
It’s a British book, meaning the specific funds and ETFs suggested are actually all available to us UKers, which is nice. There’s chapters about if and when you should employ an advisor, the merits or otherwise of sustainable investing and other useful bits and pieces.
It’s a great guide especially for anyone new to investing, but it has important lessons for us all. I am glad to have re-read it. There’s a reasonable chance, should I suddenly stumble across a big pile of money - in this economy!? lol - that I’ll feel more confident about what to do with it.

Pure nerd in-joke perfection from @KyleTrainEmoji:
PICARD: Data, shields up
DATA: Brilliant! Shields can reduce damage we sustain. Not immunity. Not hubris. Just prudence. It’s not precaution—it’s strategy.
[camera shakes]
WORF: HULL BREACHES ON NINE DECKS
DATA: Here’s what happened: you told me to raise shields, and I didn’t
IYKYK
Anti-wealth-inequality campaigner Gary Stevenson shows us how he became so rich - and what it cost him - in 'The Trading Game'
📚 Finished listening to The Trading Game A Confession by Gary Stevenson.
These days I mostly come across Gary Stevenson for his much needed ongoing anti-wealth-inequality, pro tax-the-billionaires campaigning.
Famously, he himself is a rich man, his wealth originating from his surprising career as a (financial) trader in the City of London. This book is his memoir of that period of his life, starting off from his working-class childhood of very modest means through a series of somewhat unlikely events involving him becoming “the most profitable trader at Citibank”.
The book is named after the “trading game”. That was a card game designed to reflect some aspects of financial markets, the winning of which got him a position as an intern in an investment bank. This was, and as far as I know still is, a real rarity for anyone whose parents weren’t already very wealthy and/or having had a private education.
He then goes on to make untold wealth for both the bank and himself, basically by betting on a continuous post-2008 economic crisis being forced upon the everyday person whilst the likes of him-in-his-new-position and his fellow mega-wealthy colleagues got richer and richer. He kept betting on a public economic crisis when the “professional” consensus was the economy would improve.
In particular, he took the unpopular view that historically low interest rates would remain historically low as inequality increased- and he kept winning those bets. As he says, as a trader, if you want to make money, it’s not enough to be right. You have to be right when everyone else is wrong. And this, at least as he tells it, is exactly what the situation was.
We learn a bit about the lifestyles of the average investment banker which is probably about as immoral, decadent and, on occasion, repulsive as you would imagine.
His new-found functionally unlimited wealth does not bring him health and happiness though. His personal relationships fall apart, as does his health, both physical and mental, until betting so successfully on the economic crisis has caused him enough of a personal crisis that he finally realises he’s got to give it up.
His employer, however, has different ideas for him.
The book ends before his rebirth as a pro-equality activist, although the signs are surely there. It’s a rags to riches story; where the riches are exclusively financial and came at a cost that he couldn’t tolerate. But credit is due to the guy for realising the damage that he and his colleagues were doing to the rest of us and subsequently going all-out on the campaign to stop it getting even worse.

Instagram quietly disables end-to-end encryption on your DMs
Instagram is quietly disabling the end-to-end encryption option they provided for direct messages.
Not that it’s easy to trust anything their infamously surveillance based parent company does, but still:
In 2019, Meta pledged to introduce the technology across messaging on Facebook and Instagram, saying “the future is private
In 2026, well, I suppose the plan flipped to actively remove the few privacy features they’d built.
The implications are that Meta can now read everything you send via DM.
By switching off E2EE, Instagram will now be able to access all the content of direct messages, including images, videos and voice notes.
New genetic test reveals whether or not you'd benefit from chemotherapy
A new marvel of medical science:
Groundbreaking genomic test could spare millions of breast cancer patients chemotherapy
The Prosigna test, made by the global diagnostics company Veracyte, analyses the activity of 50 genes in tumour tissue. It determines the molecular subtype and provides a score revealing the risk of breast cancer returning in the next decade, helping doctors decide if chemotherapy is worthwhile or not.
The test returns a score. The study showed that if the score was low then having chemotherapy - a famously unpleasant process to go through- had no significant positive benefit.
Five years after treatment, 95% of those who had chemotherapy and hormone therapy were alive and free from breast cancer recurrence, while 94% of those who skipped chemotherapy were also alive and recurrence-free.
The pope has (very lengthy) thoughts on AI.
I can’t pretend to have read it all yet, but the intro seems good:
Humanity, created by God in all its grandeur, is today facing a pivotal choice: either to construct a new Tower of Babel or to build the city in which God and humanity dwell together. Each generation inherits the task of shaping its own era, of guiding history to become a place where the dignity of every person is safeguarded, justice is promoted and fraternity is made possible. Yet every era also runs the risk of creating an inhumane and more unjust world.
Government department saves £ millions by replacing its Palantir IT system with an in-house one
Heartwarming stories like this reinforce how taking public IT infrastructure in-house can be not just an ethical and operational imperative, but also a financially advantageous one - despite what all the big-tech-fanboys like to think.
This, the system behind the Homes for Ukraine scheme which enabled people fleeing the war to find accommodation in the UK, is the perfect example of what all the anti-Palantir campaigners talk about, but actualised.
Palantir did their classic “hey have the system for free….for now” and, guess what, it ended up costing the taxpayer millions. Over £10 million in fact, if I understand this report correctly.
It also wasn’t very good.
…the speed of the deployment meant that it had not carried out the usual testing before it went live, and some local authorities found it confusing to use. …DLUHC has not mandated that local authorities use it, and consequently DLUHC recognises it does not have complete data on some aspects of the scheme.
The system has since been replaced with an in-house one that appears to not only leave the UK that bit less dependent on extremely weird US tech billionaire babies who spend their time publishing offensive manifestos, but also saves a lot of money and is nicer to use.
From the BBC article:
“Longer term, we wanted to replace the platform with a more flexible technology solution, enabling [MHCLG] to save significant support costs, control the system data and code,” Chan wrote.
She added its in-house replacement was “already saving MHCLG millions of pounds a year in running costs”.
MHCLG is the government department in question. Standing for “Ministry of Housing, Communities and Local Government” if that’s not obvious, which it isn’t.
User reviews are in:
“It’s easier to navigate than the previous system, safeguarding checks are easier to complete and visualise where cases have outstanding issues.”
“it’s a very user-friendly system, much easier to navigate.”
As a former government technology adviser said:
“When given suitable resources the Civil Service can often outperform private companies like Palantir,” the former government technology advisor said.
Eden added MHCLG had created a “better, easier to use, and cheaper” system.
The truth of this seems logically self-evident, but it’s nice to see 1) a concrete example of it being done in the real world, and 2) that the UK can still build good things even within its starved and diminished public sector.
For the most part I still think it would often be worth settling for a lesser IT system if it meant we weren’t dependent on the whims of the ultra-rich foreign agents who dance to the tune of their Britain-hating president.
But the truth is that’s not a choice that we have to make. We can be both less dependent on private agenda-ridden “goodwill” and also have better systems.
More of this please!
WhatsApp is being repeatedly sued alleging that it's lying about its end-to-end encryption
I obviously don’t know the truth of the situation any more than any other random person does. But it feels concerning that Meta seems to be facing at least 2 court cases accusing them of lying about how WhatsApp is super secure and, specifically, end to end encrypted. At least I think it’s two separate cases?
A new class-action lawsuit accuses Meta Platforms of misleading billions of WhatsApp users by claiming their messages are protected by unbreakable end-to-end encryption.
Filed in the San Francisco federal court, the suit alleges the company secretly stores, analyzes, and grants employee access to chat contents via internal tools.
And then there’s this:
The Texas Attorney General has sued Meta over allegations that the company’s WhatsApp messenger, used by more than 3 billion people, doesn’t provide the end-to-end encryption (E2EE) it has long claimed.
To be clear, previous investigations into the topic don’t seem to have produced a lot of evidence that this is the case - and it would be a particularly egregious sin for Meta to put out a lie of this magnitude.
But, as a previous security researcher noted, there’s no way for the average nerd in the street to know:
He said the closed source status of WhatsApp makes a definitive assessment of the code impossible
A previous audit found a different security issue with Meta employees being able to arbitrarily add anyone they wanted into otherwise private group messages, the implications of which may be dangerous given how much supposedly top secret business gets conducted via WhatsApp.
Signal apparently never had this problem - and we’d know if it did because it’s open source - so hey, why not just use that instead under the precautionary principle if nothing else? If only everyone else agreed huh.
Cash is not king, over the long term
Well this is quite the instructive chart, taken from Tim Hale’s book Smarter Investing.
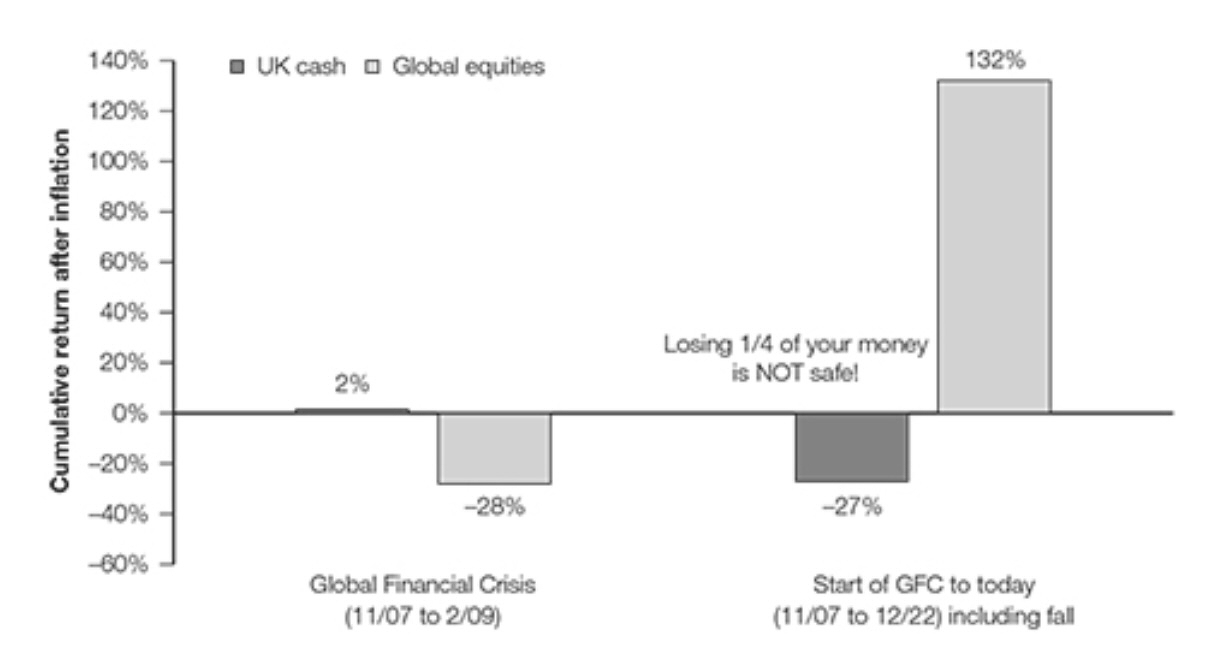
If you were unfortunate enough to have invested in global equities right before the 2007-8 financial crisis then you would have lost a whopping 28% of your investment by 2009, vs a gain of 2% if you just held cash savings. All figures after inflation taken out. Oh no. Devastating times. And it truly was for too many people.
But if you didn’t have the need (or emotional reaction) to sell out in 2009 and held to the time the book was written in 2022 - then you would have seen a gain of 132% vs a loss of 27% had you held onto your ‘safe’ cash investment, again all after inflation.
I knew cash loses value and equities on average do better but this chart helps put even the most catastrophic time in the market into a useful perspective.
Of course you’d have done even better had you only bought stocks at the nadir of the crisis. But the problem is that it’s rather hard - read impossible - to know when that is, let alone have the discipline and nerves of steel to go all in at that point. So, if what I think his theory is probably going to be is correct, far better to invest when you can - because if you end up waiting for the best time outside of the market then history suggests you’ll lose purchasing power.
Nothing here is, of course, investment advice! I haven’t even read his whole book yet :)
'More Money Than God' provides a comprehensive history of the hedge fund
📚 Finished listening to More Money Than God by Sebastian Mallaby.
This feels like a veritable encyclopedia of the history and evolution of hedge funds or, as they were originally called, back when they were invented in the middle of the 20th century, hedged funds. It’s not overly dry though; much of it is the stories of the ups and downs of various people heading these at-one-point-innovative funds.
What is a hedge fund? Well, roughly it is a private investment fund that…hedges. The idea being that unlike, say, more conventional stock funds that tend to pick stocks and hope they go up, they’re free to employ innumerable different investment strategies in all directions with the idea that no matter what happens you will have a lower risk of making a catastrophic loss whilst still capturing much of any gains in the market.
A basic example, although this is from my head rather than the book, so caveat emptor. Imagine you are convinced that a specific airline company stock is undervalued and hence going to skyrocket soon. You buy it. Then some disaster happens (e.g. a pandemic, to pick a non-random example) and every part of the airline industry shoots down in value. Sure, maybe your chosen stock was a good buy in other circumstances. But these are not those circumstances, so you lose a ton of your money, unlucky.
How could you hedge? Well, perhaps you identified another airline stock that you think might be overvalued, or even just fairly valued. Or perhaps you feel like placing a bet on a basket of all airline stocks out there. Either way, you short this stock - meaning in effect betting that it will go down. Then, if there is no pandemic then you might or might not lose money on the short but you’ll win big if you were right about the original airline stock you favoured. If there is a pandemic that temporarily destroys the whole industry then you’ll lose on your original stock pick but given you bet against another part of the same industry you will mitigate your losses with the profits you make from that trade.
Some also try to use a combination of psychology, math and economic strategies to take advantage of predictable inefficiencies in the market that are complicated enough to be unavailable to your average stock picker (and perhaps unbelievable to someone schooled in the strangely mainstream ideas of capitalism and its super efficient invisible hand, which, to my reading, is not quite what Adam Smith really had in mind, at least not in the uber-libertarian sense)
These funds tend to have certain characteristics that make them different to the average fund a retail investor might have gotten into. They’re generally accessible to only people who are provably wealthy or sophisticated investors. A random member of the public isn’t going to get direct access to them. They often require a minimum investment that will seem massive to the average retail investor. They’re generally considered risky (although this book provides some arguments in the other direction). The fees are relatively huge - typically 2% of the value of your investment plus 20% of any returns. You may be limited in how much and when you can withdraw your investment. And the fund managers tend to have their own wealth tied up into them.
Nonetheless, their freedom and flexibility has allowed some investors to make vast sums of money (and others, not so much) despite their original concept surrounding the idea of reducing market risk rather than chasing the highest returns. After all if you were right about your favoured airline stock then the hedge will reduce your profits. It’s a kind of insurance, and we all pay for insurance.
Since the 1950s they’ve become a large part in our financial system. You might be familiar with the names of some of the pioneers or managers - A. W. Jones and George Soros being perhaps the most known.
Whilst the book details some abject failures and ethical concerns with specific funds - not least how some played a substantial role in the partial destruction of various vulnerable economies and the ensuing misery that would cause the relevant country’s population - the author comes across as having a general favourable opinion of the idea. Even in its arguably distorted modern incarnations. Not least because these funds are rarely “too big to fail”. Unlike conventional banks, they didn’t need (or at least get) a tax-payer funded bailout in the 2008-era financial crisis. However, they, like most of the financial investment system, remain in my mind a totally unnecessary invention that in a perfect world probably shouldn’t exist. However, I was pleased to learn all about them from a seemingly very comprehensive history of the industry.

📚 Finished reading Dracula by Bram Stoker.
After watching Dracula: A Love Tale I realised I didn’t know and/or had forgotten the actual original Bram Stoker story of Dracula. Sure, The Count is enough of a blanket cultural artefact these days that I know what he looks like and his distinguishing behaviours. But the plot of the original story this spooky phenomenon was hugely popularised from? Not so much.
Unsurprisingly, it turns out the book is pretty great, self-evidently a classic i(f one can overlook some rather jarring sexism in places - product of its times I’m sure, etc. etc.) . The recent film turns out to have several similarities to it, although the story is deliberately entirely different. The book is very readable, highly gothic-atmospheric and truly scary in places. It’s very clear how it influenced so much of what came later in the genre.
The novel written as a series of diary entries from the various protagonists, and the occasional letter between them or newspaper article. This style I almost invariably love - in book or computer game form - and I did here. I also learned that the phrase for this is “epistolary novel” so that’ll be good for a few book searches later.
Reading the original also satiated my curiosity as to whether the more random behaviours we associate with vampires in general these days - turning into bats, not appearing in mirrors, not enjoying garlic - featured in the 1897 original Dracula vs were a more modern invention. Turns out yes, it’s a faithful representation of Count D.
To be clear though, Dracula was a populariser, not an inventor of the vampire or their famous associations. The general concept is far, far older. As far as we know the term “vampyre” first appeared in published English in 1732 in actual news reports, and, depending on one’s definition, the general concept of ‘vampirism’ may be thousands of years old.

🎥 Watched Dracula: A Love Tale.
This is a French re-imagining of the classic Dracula story. Including, unlike the original, an origin story.
He we see him convinced that his one true love, murdered in front of him in some past century, must have been reincarnated. Naturally he’ll stop at nothing to find her - even if it means hunting her through means unholy over many centuries.
The performance of Maria stood out to me, but we’ll leave it at that in case of spoilers.

📺 Watched: Curfew Season 1.
Set in a world very similar to ours, plagued by male violence against women, the government of the day comes up with an obvious, if 50% unpopular, solution. Under the ‘The Women’s Safety Act’, they instigate a legal curfew where men are not allowed to leave their house between the hours of 7pm and 7am each night, at least unless they have special permission. They’re ankle-tagged wherever they go to make sure they follow the policy.
This proves to be a rather more impactful policy than the efforts so far of real Labour’s violence against women and girls “priority”, even if it clearly hasn’t got rid of the disgusting Andrew Tate-a-likes spreading their hate on the internet. Violent crime plummets.
Nonetheless it’s not entirely eliminated. This show tells the story of what happens next after a women’s murdered body is found one morning outside of the Women’s Safety Centre, as well as frequently touching on other aspects of the social effects of such a (fictional) policy.
